문서 갱신
이 문서는 꾸준히 갱신할 계획입니다. 의견주시면 적극 반영하겠습니다.
AWS
- Upcoming AWS maintenance event occurs 는 주로 EC2의 점검 및 VM 교체 등을 알리는 이벤트이다. DataDog의 경우 Amazon EC2, Amazon Health 두 곳에서 이벤트가 발생한다.
Degraded,Degradation이라는 키워드로도 이벤트를 잡을 수 있다.
ELB
ELB/ALB 뿐 아니라 haproxy 같은 로드밸런스도 동일한 원칙에 따라 모니터링한다.
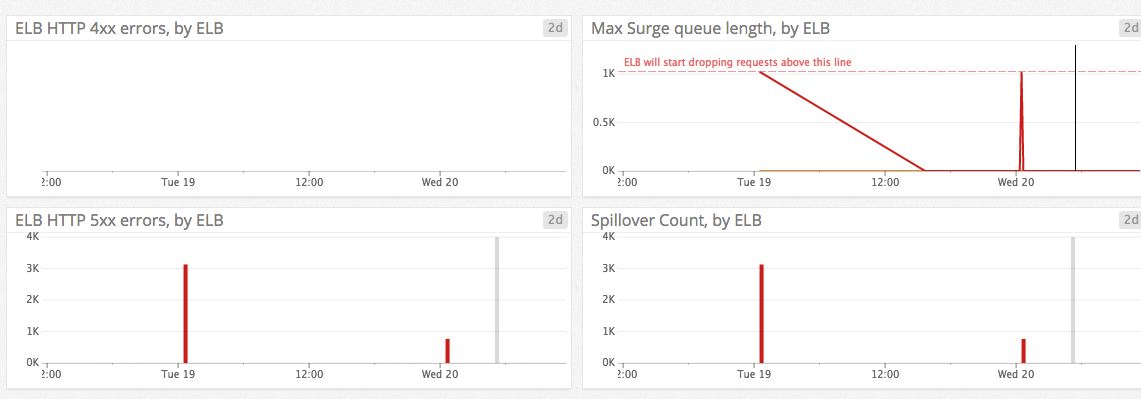
- 5xx 오류가 일정 수준 이상 발생하면 알람을 받는다.
aws.elb.httpcode_elb_5xx또는aws.applicationelb.httpcode_elb_5xx를 보자.상당수의 애플리케이션 서버는 4xx 오류도 정상적인 상황에서는 거의 발생하지 않는다. 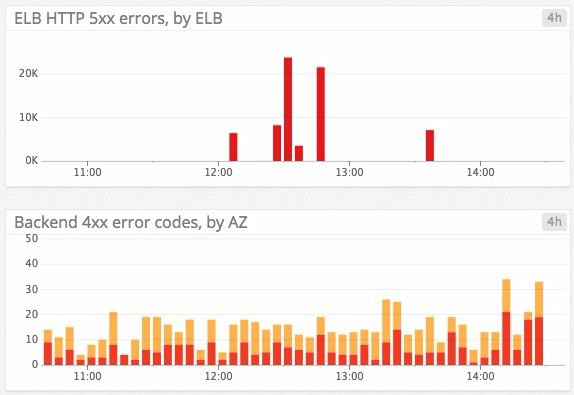
- Unhealthy host는 단 하나라도 있으면 알람을 받자.
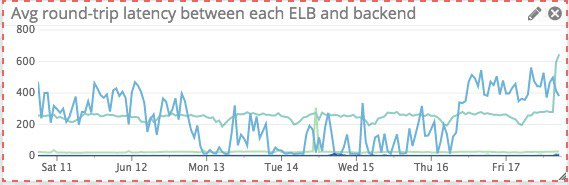
aws.elb.un_healthy_host_count - 로드밸런서와 백엔드 서비스 사이의 round-trip latency 값이 일정 수치 이상이거나 갑자기 증가했을 때 알람을 받는다. 예를 들어 배포 이후에 성능 저하가 발생해 레이턴시가 증가했다가 핫픽스로 문제가 해결되는 경우는 다음과 같은 모습을 보인다.
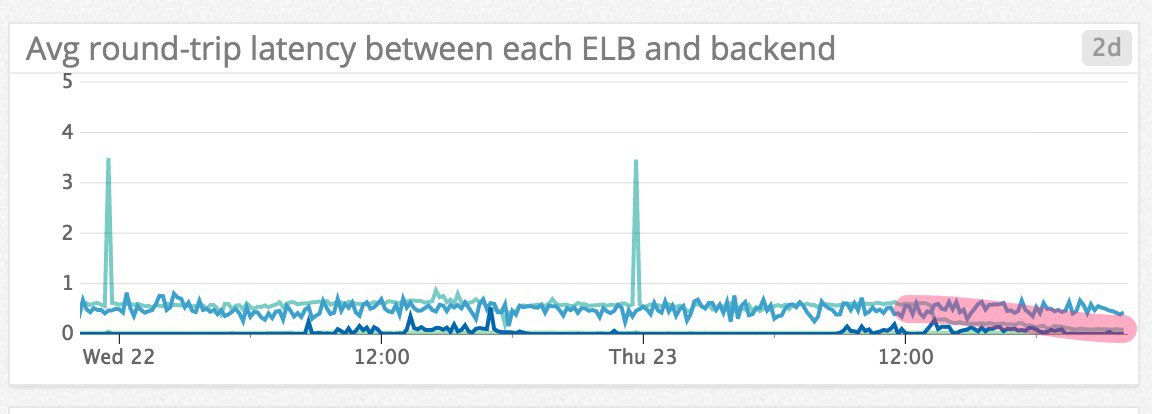
- 요청이 급격히 증가할 때 알람을 받는다. 참고: Top ELB health and performance metrics | Datadog
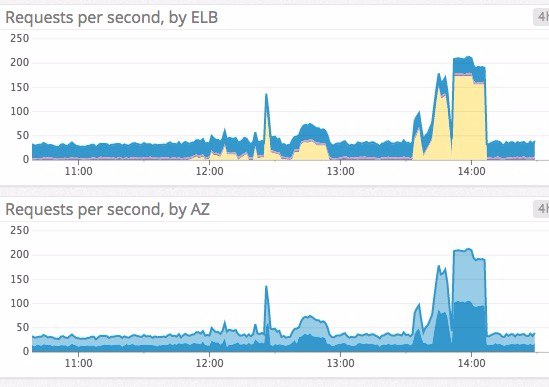
- SSL 인증서의 유효기간이 얼마 남지 않았을 때 알람을 받는다.
DataDog SSL Expires Check
호스트
- NTP sync
Network Time Protocol (NTP) Offset Issues - CPU 사용률이 일정시간 이상 높게 유지될 때 알람을 받는다. 사용률이 높다고 무조건 나쁘다고 볼 순 없다. 과거기록을 토대로 이상징후라 볼 수 있는 수치를 잡으면 된다.
- EC2 인스턴스 타입마다 수용가능한 네트워크 대역폭의 한계가 있다. 트래픽이 극도로 많은 서비스라면
network_bytes_in또는network_bytes_out등의 메트릭을 모니터링한다. - 맛이 간 EC2는 VM을 교체하자. Auto Scaling Group의 일부라서 마음대로 삭제해도 되는 인스턴스여야 마음이 편하다. Kubernetes 노드 중 일부이면 더 좋겠다.
aws.ec2.status_check_failed값이 0보다 클 때 알람을 받자.
Auto Scaling
- EC2 Auto Scaling 이 발동했을 때 알람을 받고 싶을지 모른다.
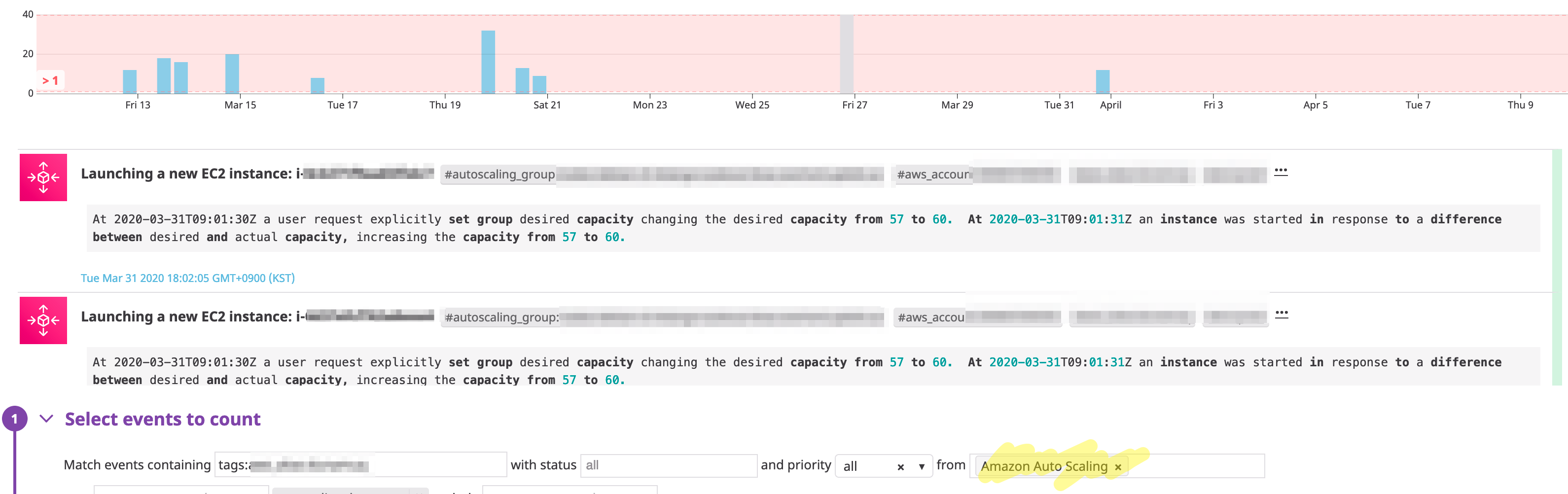
디스크
- EBS 볼륨 사용량.
aws.ebs.burst_balance값이 10% 이상인 상황이 지속적으로 발생하면 IOPS 가 부족하다는 신호이다.
프로세스
- 좀비 프로세스를 발견했을 때 알람을 받자.
- 떠 있어야 할 프로세스가 탐지되지 않을 때 알람을 받자. 예를 들어 CloudWatch Agent 프로세스가 보이지 않을 때 알람을 받는다.
네트워크
- DataDog Network Monitoring에서 Retransmit 값의 양과 추이를 살펴보자.
system.net.tcp.retrans_segs이 많으면 네트워크가 불안하다고 보면 된다.참고: Datadog Status – Elevated Web exception rate Kubernetes 의 경우 mtu 값이 최적인지 확인해보자. AWS는 Jumbo Frame 을 시도해봐도 좋다.
Kubernetes / Docker
- 메모리 사용률이 예상치를 상회하면 알람을 받는다. 일반적으로 메모리 사용량의 상한을 두기 때문에 OOM 모니터링만큼 유용하진 않다. 그래도 이상징후를 보는 지표로는 유용하다.
kubernetes.memory_usage값을pod_name별로 잡으면 Pod 당 메모리 사용률을 잡을 수 있다. - StatefulSet 는 Pod 한두 개가 내려가는 상황을 유의해보자. StatefulSet은 주로 데이터베이스와 메시지큐 등 중요 서비스이기 때문이다.
- Kubernetes Event에
CreatingLoadBalancerFailed라는 메시지가 잡히면 누군가 ExternalLoadBalancer 배포를 잘못한 것이다. InvalidSecurityGroup등 인프라스트럭처의 명세를 잘못 기술한 경우를 추척해 알람을 받자. 주로kube-system네임스페이스에서 작동하는 pods 의 로그를 분석하면 된다.- Kubernetes Autoscaler 가 작동하는 시점을 알고 싶을지 모른다.
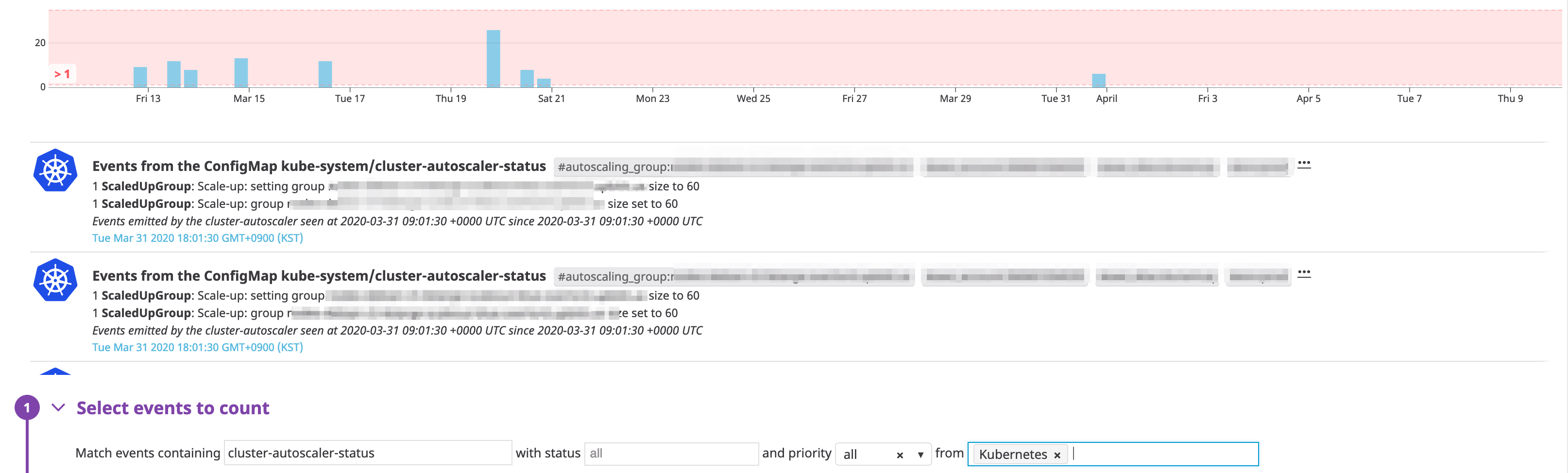
- Calico Network Policy 의 문법 오류는 Typha 의 로그에서 확인가능하다.
Validation failed; treating as missing error=error with the following fields: - kube-dns의 오류와 캐시미스 추이를 확인한다.
kubedns.error_count.count,kubedns.cachemiss_count.count등의 지표를 유심히 보면 된다.참고: Kubernetes Data Collected 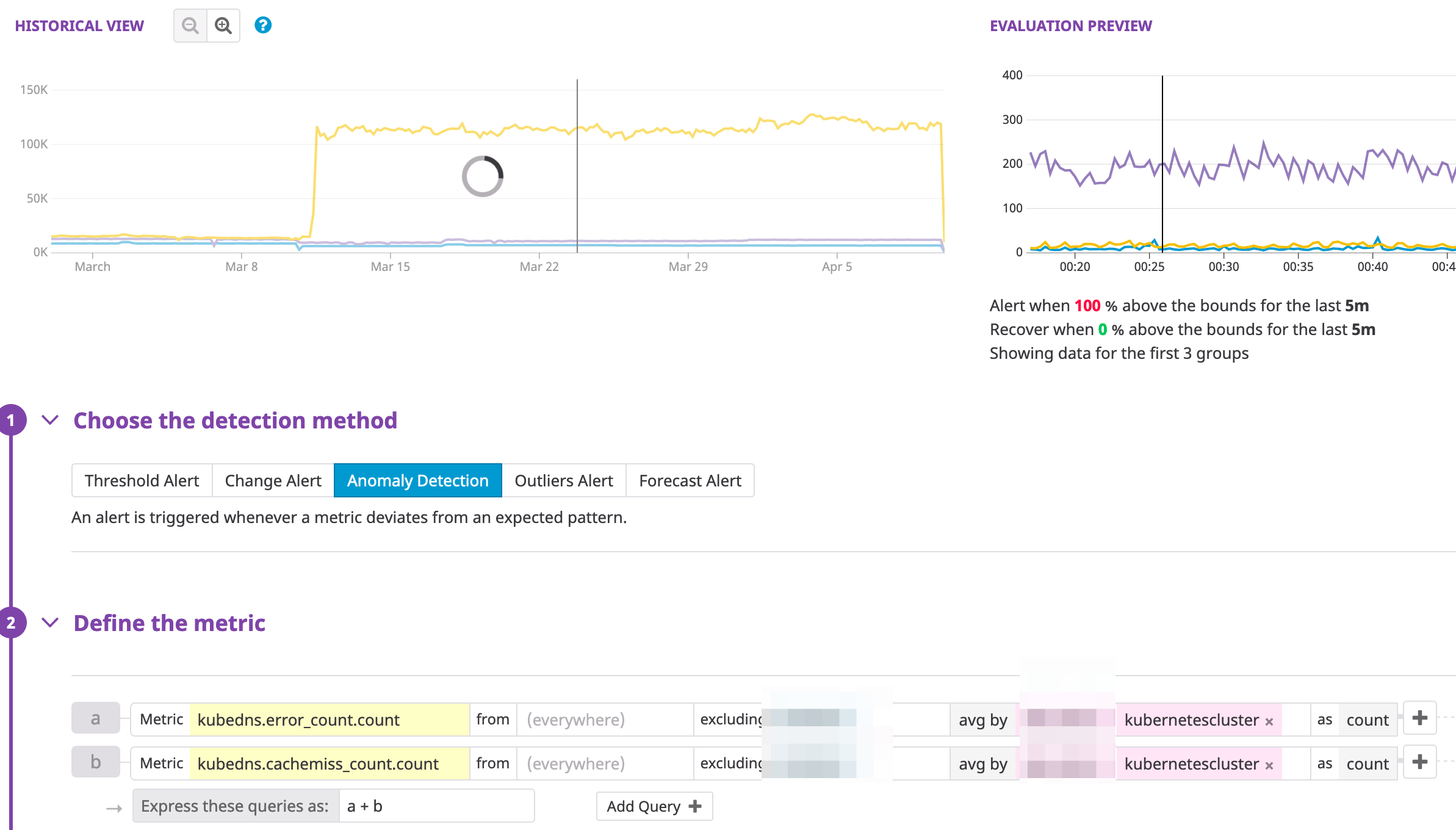
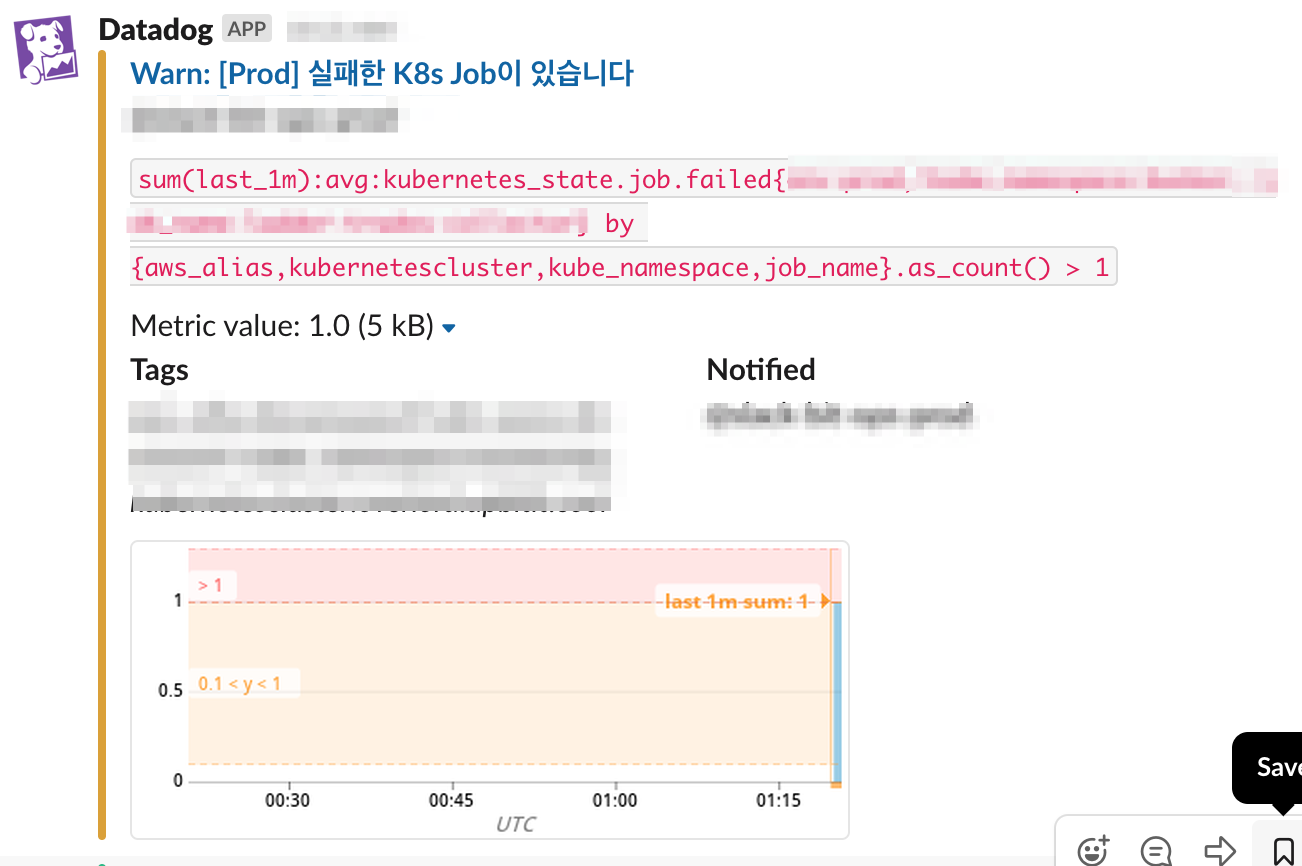
- CronJob 이 실패했을 때 알람을 받자.
JVM
OutOfMemory error
MySQL
- CPU 사용률.
- 메모리 사용률. RDS는
aws.rds.freeable_memory등의 메트릭이 유용하다. - 클라이언트 연결이 일정 수준 이상이면 알람을 받자. 최대 갯수를 넘어서서 장애가 나는 경우가 왕왕 있다. AWS RDS는
aws.rds.database_connections값을 추적하자. - 스레드가 지나치게 생성되면 알람을 받는다.
mysql.innodb.history_list_length,mysql.innodb.row_lock_waits등의 지표는 데이터베이스의 성능 추이를 판단하는데 매우 중요한 지표이다. 구체적인 원인이 무엇이 되었던 이 값이 치솟으면 응답이 느려지고 다양한 문제가 발생하기 시작한다.- 느린 쿼리가 급격히 증가하면 알람을 받는다.
어떤 쿼리가 느린지 분석하고 싶다면 Elasticsearch로 느린 쿼리 분석하기를 참고하자. - 교차 잠금을 탐지했을 때 알람을 받는다.
- IO 가 급격히 증가할 때 알람을 받는다.
- 인덱스 사용률이 낮으면 알람을 받는다.
- 캐시 적중률 등이 낮으면 알람을 받는다.
- Key cache hit rate
- Table cache hit rate
- Query cache hit rate
- Buffer pool hit rate
- Replication lag이 발생하면 알람을 받는다.
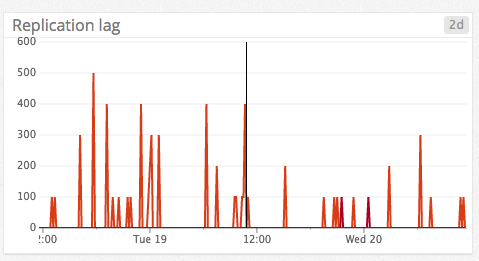
- 데이터베이스는 트래픽이 몰린다. 그러므로 호스트의 네트워크 대역폭이 충분한지 확인한다.
- Failover 가 발생하는지 확인한다.
Redis
- 싱글 코어를 이용하는 Redis는 CPU 사용률이 매우 중요한 지표이다. 대부분의 경우 10%가 넘어도 충분히 유의해야 한다. Elasticache의 경우
aws.elasticache.engine_cpuutilization메트릭을 보면 된다. Docker 인 경우redis.cpu.sys와redis.cpu.sys합친 값을aws.elasticache.engine_cpuutilization대신 보자. - 클라이언트 연결이 일정 수준 이상이면 알람을 받자.
redis.net.clients - 캐시서버는 트래픽이 몰린다. 그러므로 호스트의 네트워크 대역폭이 충분한지 확인한다.
- Failover 가 발생하는지 확인한다.
Kafka
Kafka 모니터링 에서 이 문제를 보다 깊게 다룬다.
- Replication lag이 발생하는지 확인한다.
- Unclean Leader Election
Monitoring Kafka performance metrics | Datadog 이벤트가 발생하면 알람을 받자.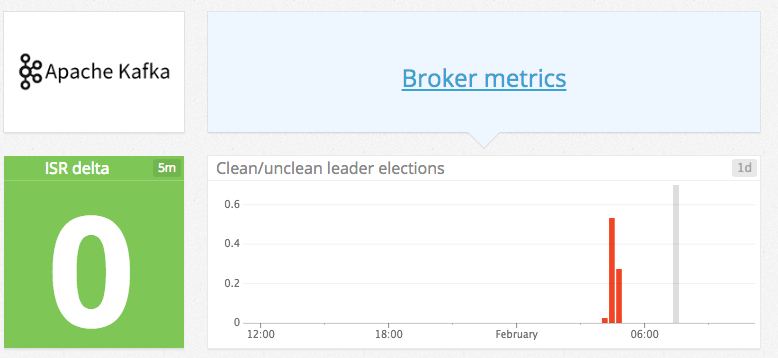
- 메시지 큐는 트래픽이 몰린다. 그러므로 호스트의 네트워크 대역폭이 충분한지 확인한다.
RabbitMQ
- Replication lag이 발생하는지 확인한다.
- 일반적으로 연결 수
rabbitmq.connections는 일정하게 유지된다. 이 값이 요동친다면 클라이언트 측의 연결 풀 설정이 제대로 됐나 확인하면 된다. 연결이 지나치게 많아도 성능이 급격히 떨어지는 요인이 된다. rabbitmq.node.disk_alarm,rabbitmq.node.mem_alarm이 1 이상이면 알람을 받는다.RabbitMQ - 트래픽이 꾸준한 곳이라면
rabbitmq.queue.messages.deliver.rate값도 특정 구간 내에서 움직인다. - 채널을 동적으로 생성 또는 삭제하지 않는 서비스가 아니라면
rabbitmq.overview.object_totals.channels값이 일정해야 한다.
참고
- 이 글은 오래 전에 쓴 Monitoring guide to DevOps를 바탕으로 작성했다.
- 데이터독 사용자가 아니라도 DataDog 블로그를 읽자. 어떤 지표를 어떻게 활용하면 좋을지 상세히 알려준다.
Author Details
Kubernetes, DevSecOps, AWS, 클라우드 보안, 클라우드 비용관리, SaaS 의 활용과 내재화 등 소프트웨어 개발 전반에 도움이 필요하다면 도움을 요청하세요. 지인이라면 가볍게 도와드리겠습니다. 전문적인 도움이 필요하다면 저의 현업에 방해가 되지 않는 선에서 협의가능합니다.
좋은 인사이트를 얻었습니다. 감사합니당
소셜이 아닌 블로그에 댓글 다는 분은 오랜만이라 너무 반갑습니다. 도움이 되어서 저도 즐겁습니다.
Redis 에서 OOM 은 어떠신가요?
제가 밟아서.. ㅋㅋ
후후 중요한 서비스는 OOM 전에 잡아야죠. 일정 수치 이상이거나 급격히 사용률이 증가할 때 알람 받는 편이 안전할 거예요. OOM 이면 어차피 프로세스가 죽었을테니 차라리 “중요 프로세스가 죽었을 때”라는 범주로 일반화하는 게 어때요?