작성일자: 2005-08-11
수정일자: 2005-08-11
인사말
아래 글의 일정 부분은 Berkeley DB ‘Programmer’s Tutorial and Reference Guide’ 문서를 번역한 것입니다. 그래서 문체가 딱딱하고 재미없을 수 있음을 사전에 경고합니다. 그래도 무턱대고 영문으로 된 문서부터 읽어야 되는 상황은 피할 수 있으니 나름 다행이라고 생각해주면 좋겠습니다.
문서가 작성된 환경
이 문서의 내용은 다음과 같은 환경에서 테스트가 이뤄졌습니다.
- Intel Pentium 4 CPU (32bits, not 64bis)
- Microsoft Windows 2000 Professional with service pack 4
- Microsoft Visual Studio .NET 2003
- Berkeley DB 4.3.28
Berkeley DB란?
Berkeley DB는 어플리케이션에 고성능, 트랜잰션 데이터 관리 서비스를 제공하는 임베디드 데이터베이스 라이브러리(embedded database library)이다. Berkeley DB는 Sleepycat Software가 개발했다. Berkeley DB는 오픈소스이므로 Open Source Definition에 명시된 라이센스에 따라 배포된다.
Berkeley DB는 어플리케이션에 직접적으로 연결되기 때문에 임베디드이다. Berkeley DB는 어플리케이션과같은 주소공간에서 운영된다. 그 결과 프로세스 간 통신(inter-process communication), 네트워크 등이 필요하지않다. Berkeley DB는 C, C++, Java, Perl, Tcl, Python, 그리고 PHP 등의 프로그래밍 언어를 위한 간단한 function-call API만을 제공할 뿐이다. 모든 데이터베이스 작업은 라이브러리 안에서 이뤄진다. 멀티프로세스, 멀티쓰레드모두 Berkeley DB 라이브러리를 통해 동시에 데이터베이스를 사용할 수 있다. 락, 트랜잭션 로깅, 메모리 관리 등 낮은 수준의 작업은 라이브러리에 의해 투명하게 운영된다.
Berkeley DB 라이브러리는 매우 이식성이 좋다. 모든 Unix 및 Linux 변종, 윈도우즈, 그리고 수많은 실시간 임베디드 운영체제에서 작동한다. 32비트 및 64비트 시스템에서 작동한다.
Berkeley DB는 SQL 같은 쿼리 언어는 지원하지 않는다. Berkeley DB는 테이블 스키마 등의 개념도 지원하지 않는다. 데이터가 어떻게 저장되고, 이를 어떻게 추출할 것인지는 전적으로 개발자에게 달렸다.
- Data Access Services
Berkeley DB 어플리케이션은 자신에게 가장 적합한 storage structure를 선택할 수 있다. Berkeley DB는 hashtables, Btrees, simple record-number-based storage, 그리고 persistent queues를 지원한다.
- Data Management Services
Berkeley DB는 동시성, 트랜잭션, 그리고 복구를 포함하는 중요한 데이터 관리 서비스를 제공한다. 이 모든 서비스가 모든 storage structures (hash tables, Btrees, simple record-number-based storage, 그리고 persistent queues) 에서 작동한다.
VC++ 환경에 Berkeley DB 설치하기
-
우선 Bereley DB의 소스코드를 다운로드 받아야 한다. http://www.sleepycat.com/ 에 가면 제약 없이 다운로드 받을 수 있다. 친절하게도 Windows Installer를 제공하기 때문에 설치과정이 무척 쉽다. 저자의 경우 Berkeley DB 4.3.28을 다운로드 받았다.
-
소스코드 설치하기
다운로드 받은 Windows Install를 실행시킨다. 저자의 경우는 파일 이름이 db-4.3.28.msi다. 이때 다음과 같은 귀여운 SleepyCat 로고를 볼 수 있다. 지시 사항에 따라 소스코드를 설치하면 된다
-
Berkeley DB 문서 보기
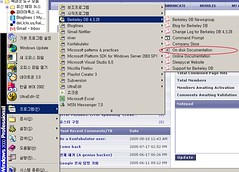
이쯤에서 Berkeley DB를 빌드하고 사용하는 법을 소개할 수도 있다. 하지만 새로운 버전이 나오면 이 문서에 소개된 것이 별 소용 없을 수 있다. 아래의 그림에 나타나듯 시작 – 프로그램 – Berkey DB 4.3.28 -On disk Documentation을 선택하면 최신 문서를 볼 수 있다.
-
Visual C++ .NET로 Win32용 Berkeley DB 빌드
영어에 약한 사람을 위해 ’On disk Documentation’ 중 ‘Building for Win32’ 문서의내용을 정리해보겠습니다. 문서 제목이 ‘Building for Win32’이긴 하지만 Win64의 경우도 다루고 있습니다. SleepyCat에 문서 제목을 변경해 달라고 요청해 볼까요?
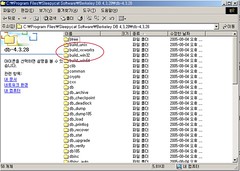
‘소스코드 설치하기’에서 선택한 설치경로로 이동합니다. 저자의 경우는 C:\Program Files\Sleepycat Software\Berkeley DB 4.3.28\db-4.3.28입니다. build_로 시작하는 몇개의 폴더가 눈에 띌것입니다. 저자의 작업 환경은 32Bit Windows Platform이기 때문에 build_win32 폴더로 들어갑니다.
-
Berkeley_DB.dsw 파일을 VS.NET IDE에서 열거나, 더블 클릭합니다.
-
프로젝트 파일을 Visual C++ 7.x용으로 변환할 것인지 묻는 창을 볼 수 있습니다. 이때 “Yes to All”을선택합니다.
-
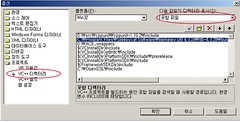
VS.NET IDE에서 Tools -> Options -> Projects -> VC++ Directories 또는 도구 -> 옵션 -> 프로젝트 -> VC++ 디렉토리를 선택합니다. “Show directories for” 또는 “다음 파일의 디렉토리 표시” 풀다운 메뉴에서 “Include files” 또는 “포함 파일”을 선택합니다. 그리고 Berkeley DB의 “build_win32” 디렉토리의 전체 경로를 추가합니다.
- “On disk Documentation”에서는 구성관리자 메뉴에서 알맞은 구성을 선택하라고 합니다. 이때 기본적으로 제공되는 구성은 Debug, Release, Debug Static 그리고 Release Static입니다. 하지만 저는 “빌드 -> 일괄빌드” 메뉴에서 모든 구성을 선택한 후 빌드했습니다. 이 편이 훨씬 편합니다.
-
Berkeley DB 주요 문서 및 참고 사이트
설명을 더 진행하기 전에 Berkeley DB의 주요 문서 및 참고 사이트에 대해 언급하겠습니다. “On disk Documentation”에는 유용한 문서가 제공됩니다. 저자는 아래 그림에 서로 다른 색깔로 표시된 4개의 문서를 주로 참고했습니다.

-
Building for Win32 문서에 대해서는 앞에서 언급했습니다.
-
C++ API 문서는 말 그대로 API 문서입니다. 목적에 따라 클래스와 메써드를 분류해 놓았습니다. 다른 문서를 참고하면서 작업하고, 필요에 따라 간간이 API 문서를 보면 됩니다.
-
C++ Getting Started Guide는 Berkeley DB를 처음사용한다면 가장 먼저 읽어야 할 문서입니다. 개발자에게 API 또는 클래스 명세서만 던져주고 "알아서해"라고 말하면 어떨까요? 십중팔구 싸움이 나거나 감정 상하는 말을 주고 받게 될 것입니다. 그래서 “Getting Started Guide” 문서가 제공됩니다. 예제를 통해 간단한 데이터베이스를 구성하고 입출력하는 연습을 할 수 있습니다.
-
Programmer’s Tutorial and Reference Guide야 말로 모든 문서 중에서 백미라고 할 수 있습니다. 가장 방대한 문서이고, 실제 상황에서 쓰일 수 있을만한 예제 프로그램을 담고 있습니다. 실제로 저자의 경우는 “Berkeley DB Transactional Data Store Applications” 섹션에서 제공된 설명과 예제를 주로 참고하여 작업했습니다. 이 문서는 앞서 설명한 세 개의 문서를 모두 포함하고있습니다. 그러므로 여러분이 문제에 봉착했고, 이 문서에서 해결책을 찾지 못한다면 앞으로 ’가나안’ 땅을 찾기 위해 황야에서 방황해야 할지도 모릅니다.
저자는 FileCollection이라는 이름의 클래스를 제작하면서 여러가지 문제에 봉착했었습니다. SleepyCat에서 제공하는 4개의 문서 외에는 유용한 자료를 찾기 힘들었습니다. 그러던 중 Techinfo라는 사이트를 알게 됐습니다. 이곳의 Berkeley DB 커뮤니티를 잘 활용하면 개발 과정에서 많은 도움을 얻을 수 있습니다. 사이트 URL은 다음과 같습니다.
Tech Info: http://www.thetechtwo.com/
FileCollection
이번에는 저자가 제작한 간단한 클래스를 분석해 보겠습니다. 이러한 분석 과정을 통해 Berkeley DB Library에 대해 보다 깊게 이해할 수 있을 것입니다. 전체 소스코드는 아래의 링크에서 다운로드 받으면 됩니다. CppUnit는 C++용 단위테스트 라이브러리입니다. 자세한 것은 http://cppunit.sourceforge.net에서 확인하기 바랍니다.
-
Environment
소스 분석에 앞서 ’Environment’가 무엇인지 이해해야 합니다. 특히 Environment와 Database의 상관관계를명확하게 이해하고, 멀티쓰레드 및 멀티프로세스 환경에서 Environment가 어떤 역할을 하는지 알아야 합니다. 다음의 설명은 Programmer’s Tutorial and Reference Guide 중 Database environment introduction부분을 번역한 것입니다.
환경(Environment)은 하나 이상의 데이터베이스, 로그, 그리고 지역파일(region files)의 추상화라고 할 수있습니다. 지역파일은 메모리 풀 캐시 페이지(memory pool cache pages)와 같은 데이터베이스 환경에 관한정보를 포함하는 공유메모리 영역입니다. 데이터베이스만이 byte-order에 독립적이고, 서로 다른 byte-order를 지원하는 기계(컴퓨터) 간의 이동이 가능합니다. 로그 파일은 같은 byte-order를 지원하는 기계 간에만 이동 가능합니다. 지역파일은 보통 특정 기계에 종속적이며, 잠재적으로 특정 운영체제 버전(operating systemrelease)에종속적입니다.
참고: 간단히 정리하자면 아래와 같은 상관관계가 성립됩니다.
Environment : Database file = 1: N Database file : Database = 1:M
Berkeley DB 어플리케이션 환경을 관리하는 가장 간단한 방법은, 같은 환경을 공유하는 모든 어플리케이션이 사용하는 파일들을 하나의 home 디렉토리에 저장하는 것입니다. Berkeley DB 자체는 Environment가 사용하는 디렉토리를 자동 생성하지 않습니다. 그러므로 개발자는 Environment를 사용하기 전에 반드시 해당 디렉토리를 생성해야 합니다.
하나의 Environment는 여러 프로세스, 또는 그러한 프로세스들 안에 있는 여러 쓰레드에 의해 공유될지도 모릅니다. 하나의 Environment가 시스템 상의 여러 디렉토리에 있는 자원(resources)를 포함하는 것도 가능합니다. 어플리케이션에 따라서는 성능 상의 이유 등으로 여러 디렉토리에 자원을 분산시키기도 합니다. 그러나 기본적으로는 데이터베이스, 공유 지역(the locking, logging, memory pool, and transaction sharedmemory areas), 그리고 로그 파일은 하나의 디렉토리 계층구조에 저장됩니다.
하나의 데이터베이스 환경을 공유하는 모든 어플리케이션은 암시적으로 서로를 신뢰한다는 것을 알아야 합니다. 그러한 어플리케이션은 서로의 데이터에 접근 할 수 있고, 버퍼공간이나 락과 같은 자원을 공유합니다. 그와 동시에, 같은 데이터베이스들을 사용하는 어플리케이션들은 반드시 하나의 환경을 공유해야 합니다. 그렇게 해야consistency가 유지될 수 있습니다.
-
FileCollection이란?
FileCollection은 몇 가지 목적 때문에 개발되었습니다.
-
기존의 MSSQL과 같은 독립적인 데이터베이스 시스템과의 통신은 성능요구사항을 만족하지 못했습니다. Berkeley DB는 임베디드 데이터베이스이기 때문에 이런 문제를 해결할 수 있습니다
-
비교적 제한된 데이터 형식만 입출력하면 되고, 조인과 같은 복잡한 데이터 조회 능력은 필요 없었습니다. FileCollection은 키/값 기반의 데이터를 처리합니다.
-
메시지 큐는 몇가지 이유 때문에 사용할 수 없었습니다. MSMQ와 같은 메시지 큐는 플랫폼에 독립적이지 않습니다. ACE Library와 같은 플랫폼 독립적인 메시지 큐를 사용할 수도 없었습니다. 데이터는 키 값에 따라 순차적으로 입력되지만, 데이터 조회 및 검색는 무작위로 이뤄집니다. FileCollection은 BTree 구조를 채택하여 이러한 상황에서 최적의 성능을 발휘하도록 했습니다.
-
비교적 간단한 요구사항 때문에 하나의 Environment에 하나의 Database만 처리하도록 만들어졌습니다.
문서에서는 전체 소스코드 중 중요하다고 생각되는 부분만 설명합니다. 그러므로 구체적인 사용 방법에 대해 알고 싶다면 소스를 다운로드 받으십시오. CppUnit 테스트 코드를 통해 사용방법을 익힐 수 있습니다.
-
-
FileCollection 생성자
FileCollection은 아래와 같은 세 개의 생성자를 기본적으로 지원합니다.
FileCollection(bool join,std::string &file,std::ostream* err_stream); FileCollection(bool join,std::string db_home,std::string data_dir, \ std::string log_dir,std::string tmp_dir,std::string &file, \ std::ostream* err_stream);이 중 가장 긴 마지막 생성자에 대해 설명하겠습니다.
-
‘키/데이터’의 데이터 형식 지정
FileCollection<char,char> collection(false,db_home,data_dir, \ log_dir,tmp_dir,db_filename,&std::cerr);‘키/데이터’의 데이터 형식이 char 배열로 선언되었습니다. 선언에 따라 int, double, 또는 구조체 등의 데이터를 모두 다룰 수 있습니다.
-
bool join
새로운 FileCollection 인스턴스가 기존에 존재하는 Environment에 참여할 것인지 여부를 나타냅니다. 멀티쓰레드 등의 환경에서 자원을 공유하고 싶을 때, 최초가 아닌 FileCollection 인스턴스는 true값을 명시해야 합니다. 아래의 예제에서는 collection_1 인스턴스와 collection_2 인스턴스가 동일한 매개변수 값으로 초기화되어 같은 자원을 공유하게 됩니다. 이때 나중에 참여하는 collection_2 인스턴스는 join값으로 true값을 받습니다.
FileCollection<char,char> collection_1(false,db_home,data_dir, \ log_dir,tmp_dir,db_filename,&std::cerr); FileCollection<char,char> collection_2(true,db_home,data_dir, \ log_dir,tmp_dir,db_filename,&std::cerr); collection_1.open(); collection_2.open(); collection_2.close(); collection_1.close(); - std::string db_home, std::string data_dir, std::string log_dir, std::string tmp_dir, std::db_filename
다음과 같이 변수 값이 할당되어 있을 경우를 생각해 보겠습니다.
db_home = “database”; data_dir = “data”; log_dir = “log”; tmp_dir = “tmp”; db_filename = “test_database.db”;
이때 디렉토리 계층구조는 다음과 같습니다. (FileCollection 클래스는 해당 디렉토리 계층구조를 자동으로 생성합니다.)
database database\data database\log database\tmp database\data\test_database.db
- std::ostream* err_stream
에러 메시지를 받을 ostream 인스턴스의 포인터입니다.
-
- Open() & Close()
FileCollection 인스턴스의 수명주기는 다음과 같이 표현될 수 있습니다.
FileCollection<char,char> collection(false,db_home,data_dir,log_dir,tmp_dir,db_filename,&std::cerr); collection.open(); // To do something collection.close();즉 인스턴스를 생성하고 멤버함수 Open()을 사용하여 Environment와 Database를 생성하거나 연다. 필요한 작업을 수행하고 나서 멤버함수 Close()를 호출하여 사용한 자원을 반환합니다.
-
Open()
Open() 함수를 호출하면 먼저 Environment 디렉토리 계층구조를 생성합니다. 앞서 설명했듯이 Berkeley DB Library는 디렉토리 계층구조를 자동으로 생성하지 않습니다. 그러므로 디렉토리 계층구조를 생성하는 코드를 추가했습니다.
디렉토리 생성 후에는 Environment 인스턴스를 생성하고 열게 됩니다. (자세한 사항은 “C++ API” 문서를 참고하십시오.) 이때 생성자의 매개변수 join 값에 따라 flag 값이 달라집니다.
const u_int32_t environment_open_flags_for_init = \ DB_CREATE | DB_INIT_LOCK | DB_INIT_LOG | DB_INIT_MPOOL | DB_INIT_TXN | DB_RECOVER | DB_THREAD; const u_int32_t environment_open_flags_for_join = DB_JOINENV | DB_THREAD; const u_int32_t database_open_flags = DB_CREATE | DB_AUTO_COMMIT | DB_THREAD;Environment를 처음으로 만들거나 사용하는 FileCollection 인스턴스는 environment_open_flags_for_init 값을 사용합니다. 이 경우에 매개변수 join 값은 false일 것입니다. 멀티쓰레드나 멀티프로세스 등의 환경에서는 한 Environment의 자원을 공유하고 싶을 수 있습니다. 이때는 join값을 true로 설정하면 되며, 이때 사용하는 FileCollection 인스턴스는 environment_open_flags_for_join 값을 사용합니다.
Environment의 경우에는 매개변수 join값에 따라 flag값이 달라집니다. 하지만 Database 생성시에는 고정 값을 사용합니다. database_open_flags 값이 그것입니다.
-
Close()
소멸자에는 자원해제 관련 정의가 전혀 없습니다. 그러므로 수동으로 Close() 함수를 반드시 호출해야 합니다. Close() 함수를 호출하더라도 Environment나 Database관련 파일이 지워지지는 않습니다. 만약 기존의 설정을 지우고 싶다면 remove_environment() 또는 remove_database() 함수를 호출해야 합니다.
-