Kubernetes 위에서 Kafka 클러스터를 운영하는 상황을 염두에 두고 설명합니다.
볼륨 늘리기
디스크 용량을 늘리기는 쉽다. Kubernetes에 내장된 볼륨 리사이징 기능을 활용하면 된다. 예를 들어 Kafka의 데이터를 담는 Persistent Volume Claim의 이름이 kafka-data-pvc 라면 kubectl edit pvc kafka-data-pvc를 쳐서 편집 모드에 들어간 후, spec.resources.requests.storage의 값을 올려 잡고 설정 값을 저장하면 된다. 간단하다.
다만 몇 가지 주의할 점이 있다.
- EBS 볼륨은 확장하는데 시간이 꽤 걸린다. 디스크 크기가 클수록 작업시간이 길어진다. 예를 들어 12TB를 16TB로 늘리려면 대략 반나절이 소요된다.
- EBS 볼륨은 최대 16TB까지 확장가능하다. 다만 16TB를 다 써서 Kafka Broker가 뜨지 않는 상태가 발생하면 복구 조치가 복잡해진다. 그러므로 평소에는 1TB 정도는 남겨놓고 확장하는 편이 낫다.
볼륨 줄이기
볼륨을 줄여야 하는가? 그럴 일은 없기를 바란다. 왜냐? AWS EBS는 볼륨 축소를 지원하지 않고 이는 K8s도 마찬가지이기 때문이다. 현실적으로 Kafka 클러스터 복사본을 만들고 복사본으로 원본을 대체하는 것이 볼륨을 축소하는 가장 쉬운 방법이다. 다만 Kubernetes의 PVC와 PV는 대체로 Immutable 하므로 교체 작업이 녹녹하지 않다. 이론적으론 가능하지만 사람이 실수하기 딱 좋은 작업 과정의 반복이다.
그러므로 볼륨을 교체하기보단 다음과 같은 절차를 따르는 편이 낫다.
- Kafka 복사본을 만든다. 복사하는 방법은 조금 있다 이야기하자.
- Kafka 원본을 비우거나 새로 만든다. 이때 볼륨 크기를 원하는만큼 줄인다.
- 복사본에서 새 Kafka로 데이터를 적재한다. 최초에 복사본을 만드는 과정을 거꾸로 반복 실행하면 된다.
- Kafka 복사본을 삭제한다.
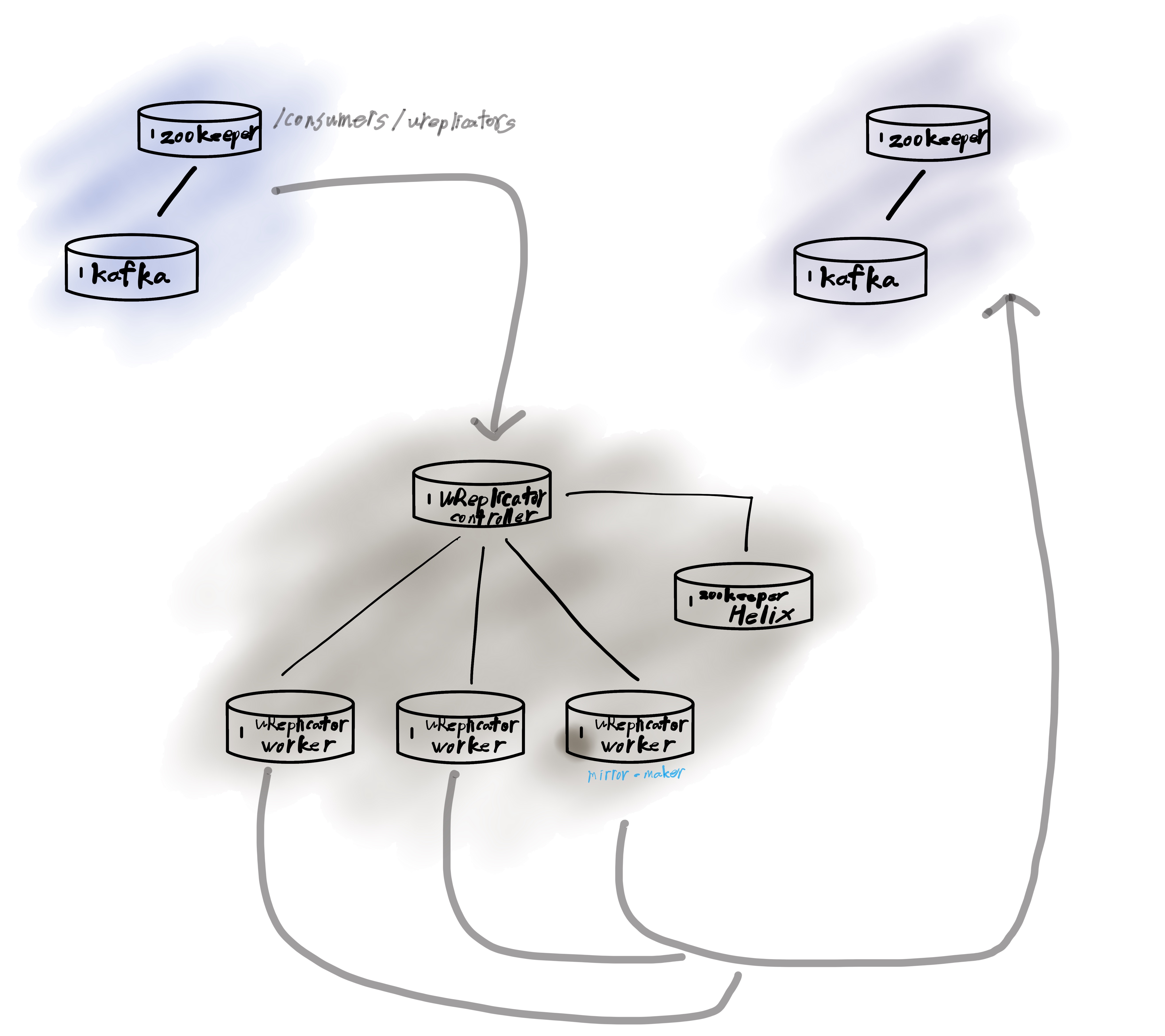
Kafka를 어떻게 복사하는가?
Kafka는 mirror-maker 라는 유틸리티를 제공한다. 이 도구는 원본에서 데이터를 읽어서 복사본으로 전송한다. 그리고 Uber는 uReplicator 라는 도구를 오픈소스로 공개했다.
이 도구는 기본적으로 mirror-maker 를 여러 대 동원해서 더 빠르고 안정적으로 데이터를 이전한다. uReplicator 는 사용자층이 많지 않고 문서가 친절한 편은 아니다. 그래서 처음에 접근하기 쉽지 않다. 따라서 K8s에서 바로 쓸 수 있는 예제를 만들어두었다. 예제를 이용해 운영하면 크게 어려운 점은 없으리라 본다.
[…] Kafka의 디스크가 모자랄 때 […]