책 스캔하기에서 문자 광학 인식(OCR)을 직접 처리해 종이책 스캔 비용을 절약하면 된다고 했습니다. 이번에는 Acrobat의 OCR 메뉴가 어디 있는지 어떤 옵션이 있는지 간단히 알아봅니다.
우선 메뉴부터 찾아봅시다.
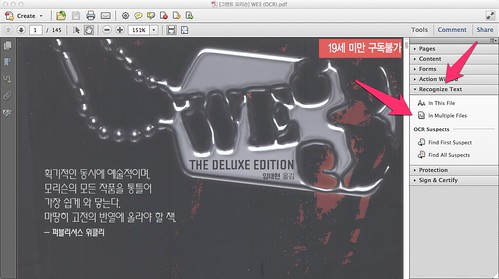
지금 열린 문서를 처리할지 다른 여러 문서를 한꺼번에 처리할지 선택합니다. 보통 종이책을 여러 권 보내서 스캔하므로 후자를 선택해봅니다.
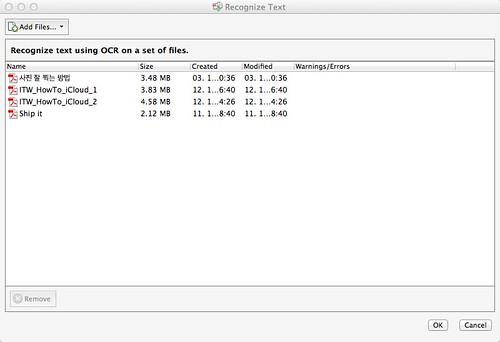
이렇게 책을 여러 권 선택하고 OK 버튼을 누르면 OCR 옵션이 나옵니다.
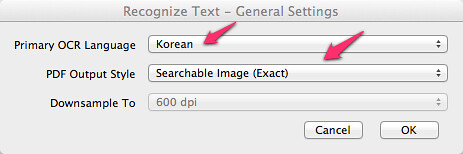
한국어 책이므로 언어는 당연히 Korean입니다. 그 다음이 중요한데 알고리즘은 Searchable Image (Exact)를 권장합니다. 경험을 토대로 각 옵션을 비교하자면,
Searchable ImageSearchable Image (Exact)보다 결과가 덜 정확합니다.- 원본의 손상이 없습니다.
Searchable Image (Exact)- 정확하지만 처리 과정이 느립니다.
- 원본의 손상이 없습니다.
ClearScan- 정확하고 빠릅니다.
- 원본이 손상 당할 위험이 있습니다.
이게 전부입니다. OCR은 시간을 많이 잡아먹기 때문에 5권이 넘으면 자기 전에 작업을 걸어놓는 편이 좋습니다.
Author Details
Kubernetes, DevSecOps, AWS, 클라우드 보안, 클라우드 비용관리, SaaS 의 활용과 내재화 등 소프트웨어 개발 전반에 도움이 필요하다면 도움을 요청하세요. 지인이라면 가볍게 도와드리겠습니다. 전문적인 도움이 필요하다면 저의 현업에 방해가 되지 않는 선에서 협의가능합니다.