변경 내역
-
2006.07.29 작성.
이 글은 월간 마이크로소프트웨어(일명 마소) 2006년 6월호 프로그래밍 노트 칼럼에 기고한 글입니다. 물론 구성이나 내용 상의 차이가 있을 수 있습니다.
XML 직렬화 (XML Serialization)
지난 시간에는 MIME 파서를 구현해봤다. 첫 번째 파서는 시작 줄에서부터 마지막 줄까지의 문자열을 한 줄씩 읽어서 합쳐(Concatenation)나갔다. 이와 달리 두 번째 파서는 시작 지점과 마지막 지점을 찾은 다음 String::Substring 메써드로 필요한 문자열만 잘라냈다. 이렇게 함으로써 문자열 생성에 필요한 메모리 공간과 CPU 시간을 획기적으로 줄일 수 있었다.
이번에는 지난번과는 정반대로 이미 만들어져 있는 문자열의 일부를 빼내는 것이 아니라, 거대한 문자열을 만들어 나갈 것이다. 특히 .NET Framework 어플리케이션, 그 중에서도 웹 서비스에 많이 쓰이는 XML 직렬화(XML Serialization) 기능을 구현해 볼 것이다. 어떻게 하면 직렬화의 성능을 극적으로 끌어올릴 수 있는지 알아보자.
회원정보 객체를 XML로 표현해 보자.
<리스트 1>과 같은 회원정보 객체(Customer)가 있다. 객체는 회원의 이름과 주소를 표현한다. 이때 회원의 거주지는 하나 이상의 배열로 표현된다. 나초보씨는 서울 토박이다. 서울의 모 고등학교를 졸업한 그는 대전 소재의 KAIST에 입학했다. 그래서 나초보씨는 집과 기숙사 주소 모두를 입력했다.
<리스트 2>는 나초보씨의 정보를 XML로 표현한 것이다. 루트 엘레멘트 <Customer> 밑에 엘레멘트 <Name>과 <Address>가 있다. 각각 나초보씨의 이름과 주소를 표현한다. <Address>는 두 번 반복되며 각각 서울 집주소와 대전 기숙사 주소를 나타낸다.
이제 <리스트 1>의 Customer 객체를 <리스트 2>의 XML로 변환시키기 위한 코드를 작성해보자.
<리스트 1> 회원정보 객체
public class Address
{
public string[] Street;
public string City;
public string State;
public string ZipCode;
}
public class Customer
{
public string Name;
public Address[] Address;
}
<리스트 2> 회원정보 XML
<?xml version="1.0" encoding="utf-16"?> <Customer xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3. org/2001/XMLSchema-instance" xmlns="http://example"> <Name>나초보</Name> <Address ZipCode="149-720"> <StreetName> <Name>노원구 중계본동</Name> <Name>꾀꼬리 아파트 xx동 yy호</Name> </StreetName> <City>서울</City> <State>-</State> </Address> <Address ZipCode="305-701"> <StreetName> <Name>유성구 구성동</Name> <Name>373-1번지</Name> </StreetName> <City>대전</City> <State>-</State> </Address> </Customer>
첫 번째 시도 – System.String::Concat
지난 호와 마찬가지로 이번에도 첫 시도는 String::Concat이다. 일반적으로 C#에서 문자열을 합칠 때는 + 연산자가 많이 쓰인다. C# 컴파일러는 두 개의 String 인스턴스에 대한 + 연산을 String::Concat 메써드 호출로 변환한다.
<리스트 9> ‘+’ 연산자의 Intermediate Language 변환
class Program
{
static void Main(string[] args)
{
string org = "Concat";
string dst = org + "Test";
}
}
.method private hidebysig static void Main(string[] args) cil managed
{
.entrypoint
// Code size 19 (0x13)
.maxstack 2
.locals init ([0] string org)
IL_0000: ldstr "Concat"
IL_0005: stloc.0
IL_0006: ldloc.0
IL_0007: ldstr "Test"
IL_000c: call string [mscorlib]System.String::Concat(string,
string)
IL_0011: pop
IL_0012: ret
} // end of method Program::Main
<리스트 3>은 + 연산을 활용한 객체 직렬화의 예제다. 지난번에 지적했던 바와 같이 System.String 인스턴스는 읽기 전용(Immutable)이다. 그러므로 + 연산이 실행될 때마다 하나의 연속된 메모리 공간에 문자열이 만들어지는 것이 아니라, 별도의 공간에 새로운 객체가 생성되는 것이다. 이를테면 <리스트 4>와 같은 메모리 할당 구조를 갖게 된다.
<리스트 3> String::Concat을 활용한 XML Serialization
public class Address
{
public string[] Street;
public string City;
public string State;
public string ZipCode;
public string BuildXml()
{
string xmlStr += " <Address ZipCode=\"" + ZipCode + "\">" + Environment.NewLine;
xmlStr += " <StreetName>" + Environment.NewLine;
foreach(string street in Street)
{
xmlStr += " <Name>" + street + "</Name>" + Environment.NewLine;
}
xmlStr += " </StreetName>" + Environment.NewLine;
xmlStr += " <City>" + City + "</City>" + Environment.NewLine;
xmlStr += " <State>" + State + "</State>" + Environment.NewLine;
xmlStr += " </Address>";
return xmlStr;
}
}
public class Customer
{
public string Name;
public Address[] Address;
public string BuildXml()
{
string xmlStr += "<?xml version=\"1.0\" encoding=\"utf-16\"?>" + Environment.NewLine;
xmlStr += "<Customer xmlns:xsd=\"http://www.w3.org/2001/XMLSchema\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\" xmlns=\"http://example\">" + Environment.NewLine;
xmlStr += " <Name>" + Name + "</Name>" + Environment.NewLine;
foreach(Address address in Address)
{
xmlStr += address.BuildXml() + Environment.NewLine;;
}
xmlStr += "</Customer>" + Environment.NewLine;;
return xmlStr;
}
}

<리스트 4> String::Concat 연산 후의 메모리 할당 구조
두 번째 시도 – System.Text.StringBuilder
확실히 String::Concat은 매번 새로운 객체를 생성하기 때문에 메모리 및 CPU의 효율적인 사용과는 거리가 먼 방법이다. 어떻게 하면 보다 효율적으로 자원을 사용할 수 있을까? <리스트 2>와 같은 회원정보 XML을 생성할 만큼 충분한 메모리를 미리 할당 받아 놓는 방법이 있지 않을까? "ABCDE"와 같이 길이가 5인 문자열 5개를 연달아 붙여서 길이가 25인 새로운 문자열을 생성해야 한다면, 미리 길이 5 x 5 = 25, 즉 5 x 5 x 2 = 50 바이트짜리 버퍼를 만드는 것이다. C 또는 C++에서는 strncpy 함수 등으로 이러한 연산을 할 수 있다. 그러나 .NET Framework는 문자열에 대한 직접적인 메모리 접근을 허용하지 않기 때문에 대안으로 StringBuilder를 제공한다.
StringBuilder는 내부적으로 String 버퍼를 갖고 있다. StringBuilder::Append 메써드를 호출할 때마다 새로운 String 인스턴스를 생성하는 대신 strncpy처럼 버퍼 뒤쪽에 매개변수로 받은 문자열을 복사해 넣는다. 이때 새로운 문자열을 생성하기에 버퍼가 충분하지 않을 수 있다. 이런 경우에는 새로운 버퍼를 할당 받고, 이전 버퍼의 데이터를 모두 복사해 넣는다. 새로운 버퍼의 크기는 이전 것의 두 배로 설정된다. StringBuilder의 구현과 성능에 대한 논의는 이쯤에서 잠시 멈추고, StringBuilder의 생성자를 살펴보자.
<리스트 8> StringBuilder의 생성자 시그너처
public StringBuilder(); public StringBuilder(int capacity); public StringBuilder(int capacity, int maxCapacity); public StringBuilder(string value); public StringBuilder(string value, int capacity); public StringBuilder(string value, int startIndex, int length, int capacity);
<리스트 8>은 StringBuilder 생성자의 시그너처이다. 주의해서 봐야 할 부분은 정수형 매개변수 capacity 다. 매개변수 capacity는 StringBuilder 인스턴스의 초기 버퍼 크기를 지정한다. 만약 StringBuilder 생성 시에 초기 버퍼의 크기를 정해주지 않는다면, 기본값으로 16 문자열로 설정된다. 여기서 버퍼의 크기가 바이트 단위로 표현되지 않는다는 점에 주의해야 한다. 일부 문서에는 버퍼의 크기가 바이트로 표현되는데 이는 틀린 것이다. 만약 버퍼의 크기가 16이라면 실제로는 32바이트가 할당될 것이며, .Net Framework에서는 문자 하나 당 2바이트를 차지하는 UTF-16으로 인코딩되므로 버퍼는 16개의 문자를 담을 수 있게 된다.
StringBuilder의 생성자를 살펴봤으니, 이제 다시 성능 문제에 대해 논의해보자. 앞서 StringBuilder는 문자열을 병합할 버퍼 공간이 부족할 때마다 기존 것의 두 배 크기로 새로운 버퍼를 할당 받는다고 했다. 그러므로 초기 버퍼의 크기를 지나치게 작게 설정하면, 문자열의 크기가 버퍼 크기보다 커질 때마다 새로운 버퍼 할당 및 데이터 복사에 귀중한 자원을 낭비할 수 있다. 길이가 5000이 넘는 문자열이 생성되는데 초기 버퍼 크기를 16으로 잡았다면, 버퍼의 크기는 16, 32, 64, 128, 256, 512, 1024, 2048, 4096, 8192으로 계속 바뀌게 된다. 이와 반대로 결과물의 크기를 제대로 예측하지 못해서 초기 버퍼의 크기를 지나치게 크게 잡는 것도 문제다. 초기 버퍼의 크기가 5000이었는데 정작 병합된 문자열의 길이는 500에 불과했다면, 결과적으로 4500 바이트를 더 할당하느라 자원을 낭비한 셈이 된다.
말은 쉽지만 대부분의 경우에 StringBuilder의 초기 버퍼 값을 적절하게 잡는 것은 쉬운 일이 아니다. 그렇다고 해서 지나치게 걱정할 필요는 없다. <리스트 7>에서 알 수 있듯이 최종 문자열의 길이가 충분히 긴 경우에는 기본값인 16으로 StringBuilder를 생성한 경우라도 String::Concat에 비해 월등한 성능을 보여주기 때문이다. 물론 이 글에서 사용한 예제에서는 XML 문자열의 길이가 1000 단위이므로 초기 버퍼 값을 적절하게 설정하면 어플리케이션의 수행 속도가 상당히 향상될 것이다.
<리스트 5>는 <리스트 2>의 String::Concat을 StringBuilder로 대체한 소스 코드다. + 연산자를 StringBuilder:Append 메써드로 바꾸었을 뿐 크게 달라진 점은 없다.
<리스트 5> StringBuilder의 생성자 시그너처
public class Address
{
public string[] Street;
public string City;
public string State;
public string ZipCode;
public void BuildXml(StringBuilder sb)
{
sb.Append(" <Address ZipCode=\"");
sb.Append(ZipCode);
sb.Append("\">");
sb.Append(Environment.NewLine);
sb.Append(" <StreetName>");
sb.Append(Environment.NewLine);
foreach(string street in Street)
{
sb.Append(" <Name>");
sb.Append(street);
sb.Append("</Name>");
sb.Append(Environment.NewLine);
}
sb.Append(" </StreetName>");
sb.Append(Environment.NewLine);
sb.Append(" <City>");
sb.Append(City);
sb.Append("</City>");
sb.Append(Environment.NewLine);
sb.Append(" <State>");
sb.Append(State);
sb.Append("</State>");
sb.Append(Environment.NewLine);
sb.Append(" </Address>");
}
}
public class Customer
{
public string Name;
public Address[] Address;
public void BuildXml(StringBuilder sb)
{
sb.Append("<?xml version=\"1.0\" encoding=\"utf-16\"?>");
sb.Append(Environment.NewLine);
sb.Append("<Customer xmlns:xsd=\"http://www.w3.org/2001/XMLSchema\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\" xmlns=\"http://example\">");
sb.Append(Environment.NewLine);
sb.Append(" <Name>");
sb.Append(Name);
sb.Append("</Name>");
sb.Append(Environment.NewLine);
foreach(Address address in Address)
{
address.BuildXml(sb);
sb.Append(Environment.NewLine);
}
sb.Append("</Customer>");
sb.Append(Environment.NewLine);
}
}
1차 분석 – String::Concat vs. StringBuilder
상상해보자. MS의 Passport 인증과 같이 한 회사가 보유한 회원 정보를 다른 회사가 이용하는 서비스가 필요하다. 이 서비스를 Ticket 서비스라고 부르자. 그런데 보안상의 문제 때문에 웹 서버 포트(80)만 사용하고 싶다. 게다가 비즈니스 환경이 변하면 공유하는 정보의 포맷도 쉽사리 바뀔 수 있으므로, 융통성 있는 포맷을 사용하고 싶다.
이러한 조건 때문에 Ticket 서비스를 웹 서비스로 구축하기로 했다. 여러 업체가 사용할 서비스이므로 성능 문제가 매우 중요하다. 그래서 CLRProfiler로 <리스트3>와 <리스트 5>의 직렬화 코드를 점검해 보았다. <리스트 7>에 상세한 결과가 제시되어 있다.
StringBuilder의 초기 버퍼 크기를 최적화하지 않았음에도 StringBuilder가 String::Concat 보다 월등히 나은 성능을 보여준다. 처리량(반복회수)이 많아질수록 이러한 차이가 두드러진다.
2차 분석 – String::Concat은 언제 사용하는가?
이쯤 되면 성능면에서 탁월한 StringBuilder를 놔두고, String::Concat을 사용하는 경우가 많은지 의문이 생길 수 있다. 필자가 지켜본 몇몇 개발자는 서너 개의 문자열을 병합하는 작업에도 StringBuilder를 애용하는 충실함을 보여줬었다. String::Concat 또는 + 연산자의 장점이라고는 소스 코드의 길이가 줄어든다는 것 뿐이라고 생각했던 것이다. 그러나 이는 사실과 다르다.
작은 크기의 문자열 병합 연산일 경우에는 StringBuilder를 사용하지 않는 편이 낫다. 작은 크기의 문자열에 대해 String::Concat 연산을 몇 차례 수행하는 것은 성능 저하 효과가 크지 않다. 길이가 d인 문자열을 n회 병합하면 성능은 d + 2d + 3d + … + nd = n(n + 1)d/2 이다. 초기 버퍼의 크기가 최적화되었을 경우라면 StringBuilder의 성능은 O(dn) 정도다. 이제 (n, d) = (3, 3) 인 경우를 생각해보자. 예측대로라면 String::Concat 연산은 n(n + 1)d / 2 만큼 걸리고, StringBuilder는 dn = 9 만큼 소요될 것이다. 그러나 실제로는 전혀 반대의 상황이 벌어진다. StringBuilder는 매우 복잡한 객체이기 때문에 객체 생성 등에 따르는 오버헤드가 크기 때문이다.
StringBuilder의 대안 – System.Xml.Serialization.XmlSerializer
StringBuilder를 이용한 직렬화 코드는 성능 면에서는 일단 합격점을 받았다. 그러나 객체가 크고 복잡해질수록 직렬화 코드를 작성하는 것은 고역이 된다. Ticket 서비스 개발 팀은 이러한 수작업에 실증 나기 시작했다. 그래서 대안을 찾아보기로 했다.
MSDN을 살펴보던 그들은 범용 XML 직렬화 기능이 지원된다는 사실을 알게 됐다. <리스트 6>는 .Net Framwrok의 직렬화 기능을 활용했다. 단순히 클래스의 공개 멤버변수에 애트리뷰트 (Attribute)를 다는 것으로 복잡한 직렬화 코드를 대신할 수 있었다.
이렇게 편의성은 증가했지만 성능을 측정해 보기 전에는 상용 서비스 도입 여부를 결정할 수 없다. 종전에 한 차례 살펴본 <리스트 7>에 새로운 코드의 프로파일링 결과가 제시되어 있다.
처리량(반복회수)이 적을 때는 세 가지 방법 중 가장 메모리를 많이 사용한다. (또한 가장 느리다.) 그러나 처리량 증가에 따른 메모리 증가량(기울기)은 StringBuilder와 String::Concat의 평균치 정도이다. 결론적으로 XmlSerializer를 사용하면 개발 시간이 단축된다. 하지만 XmlSerializer는 문자열 병합을 위해 내부적으로 StringBuilder를 사용하지만 객체 정보 수집을 위해 리플렉션 기능을 사용하는 등 다른 작업도 많이 한다. 그러므로 최적의 성능은 낼 수 없다. 그러나 최악의 성능을 보이는 것은 아니다. 결국 어느 것에 비중을 두느냐에 따라 StringBuilder와 XmlSerializer를 선택하게 된다.
<리스트 6> XmlSerializer를 활용한 XML Serialization
public class Address
{
[XmlArray("StreetName")]
[XmlArrayItem("Name")]
public string[] Street;
[XmlElement]
public string City;
[XmlElement]
public string State;
[XmlAttribute]
public string ZipCode;
}
[XmlRoot("Customer", Namespace="http://example")]
public class Customer
{
[XmlElement]
public string Name;
[XmlElement]
public Address[] Address;
}
class Program
{
[STAThread]
static void Main(string[] args)
{
Customer customerInstance = new Customer();
// 생략......
XmlSerializer serializer = new XmlSerializer(typeof(Customer));
StringWriter sw = new StringWriter();
serializer.Serialize(sw, customerInstance);
string xmlStr = sw.ToString();
}
}
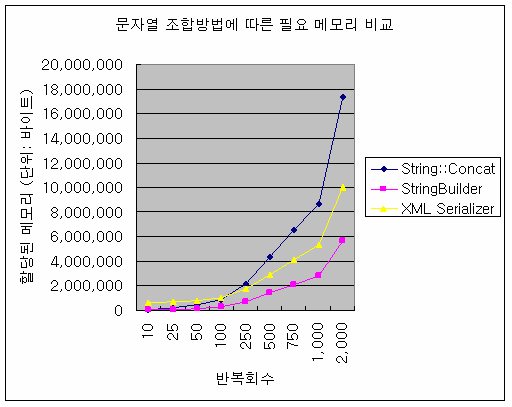
<리스트 7> 문자열 조합방법에 따른 필요 메모리 비교 (통계자료 다운로드)
XmlSerializer 최적화하기
<리스트 7>을 다시 들여다보자. 초기 구간에서 XmlSerializer와 StringBuilder의 선이 거의 평행에 가깝다는 사실을 알 수 있다. 이는 무엇을 의미하는 걸까?
앞서 XmlSerializer는 객체의 정보를 먼저 수집한다고 했다. 그러나 객체가 가진 멤버 변수의 개수나 종류는 동적으로 변하지 않는다. 그러므로 직렬화 할 때마다 이 작업을 반복하는 것은 낭비다. XmlSerializer는 최초 실행 시에 해당 객체를 직렬화하는 데 필요한 코드를 임시 어셈블리 형태로 컴파일하여 로드한다. 이후로는 객체 분석 작업 등을 다시 수행하지 않고, 임시 어셈블리의 코드를 사용한다. 초기 구간에서 메모리 사용의 차이 중 상당수는 임시 어셈블리가 로드된 공간만큼의 차이다.
한가지 주의할 점은 XmlSerializer를 생성할 때, 직렬화할 객체 타입을 매개변수로 받는 생성자를 선택해야 한다는 사실이다. 그렇지 않으면 임시 어셈블리를 재활용하지 않고, 직렬화할 때마다 새로운 코드를 생성하여 사용하게 된다.
또 한가지 재미있는 것은 직렬화 코드를 꼭 런타임에 만들 필요가 없다는 사실이다. MVP.XML Library를 사용하면 컴파일 시에 미리 직렬화 코드를 생성할 수 있다. 이것은 동적 컴파일에 필요한 시간을 제거함으로써 어플리케이션이 처음 구동 되었을 때의 성능을 향상시킬 수 있다.
결론
이번 시간에는 가장 효율적인 문자열 병합 방법을 알아내기 위해, 서로 다른 세 가지 XML 직렬화 코드를 분석해봤다. 여기서는 지면 상의 이유로 String::Concat이 더 효율적인 경우를 보여주지 못했다. 그러나 일회성으로 작은 크기의 문자열을 생성할 때는 String::Concat이 오히려 빠르다.
이와 달리 큰 문자열을 반복해서 생성해야 한다면 StringBuilder가 제격이다. StringBuilder는 내부에 충분한 버퍼를 갖고 있기 때문에, 문자열 병합 시에 인스턴스를 새로 생성해야 하는 오버헤드가 줄어든다. 하지만 StringBulider는 사용하기 불편하다는 단점이 있다. <리스트 5>을 보면 알 수 있듯이 세 가지 방법 중 소스 코드가 가장 길다.
이에 대한 대안으로 XmlSerializer를 생각해 볼 수 있다. 공개된 멤버변수에 애트리뷰트를 다는 것만으로 앞선 직렬화 코드를 대신할 수 있었다. 가장 빨리 개발할 수 있는 방법이고, 가독성 등이 좋아서 유지보수작업에 들어가는 비용을 줄여준다. 하지만 StringBuilder를 직접 사용하는 방법과 비교해서 성능이 많이 떨어지는 것이 사실이다.
여러분은 StringBuilder와 XmlSerializer의 장단점을 숙지하고, 요구사항에 따라 적합한 방법을 선택할 수 있어야 한다. 다음 회에도 성능 문제에 관해 논의할 생각이다. 그러나 지금까지와는 달리 고기를 잡는 법에 중점을 둘 생각이다.
참고 문헌
C# 성능향상에 관한 글을 참조하기 바란다.